Why Distributed Training Matters
Training deep learning models on a single GPU is often slow or even infeasible for larger architectures and datasets. Distributed Data Parallel (DDP) in PyTorch enables multi-GPU training by replicating models across processes and synchronizing gradients efficiently, offering performance and scalability advantages over legacy approaches like Data Parallel (DP). This exploration began while reproducing GPT-2 from scratch and wanting to understand how to scale training effectively.
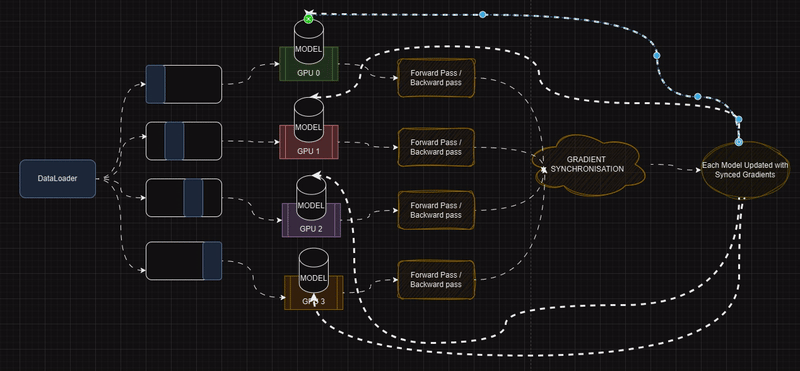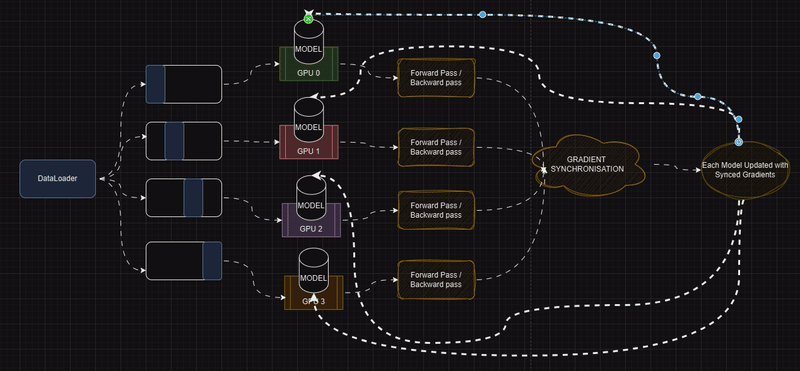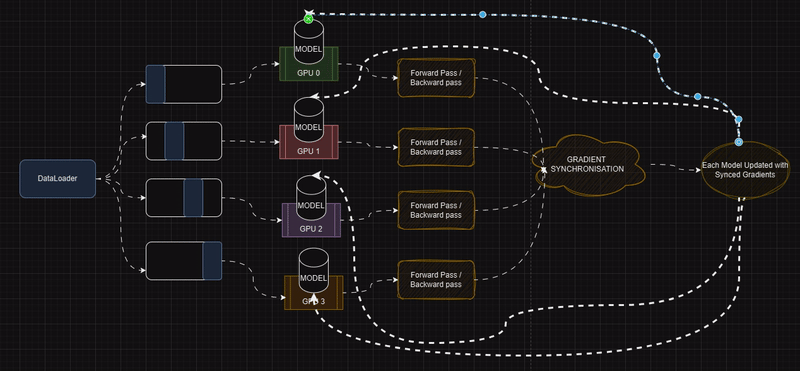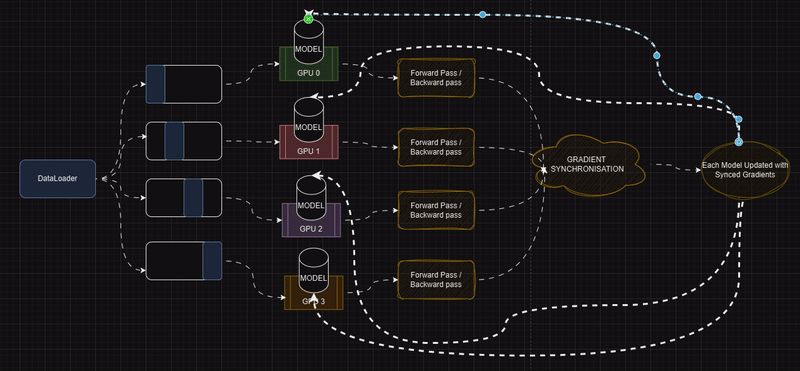
Distributing training across GPUs reduces time and enables larger models to be trained.
DP vs DDP: What’s the Difference?
PyTorch’s Distributed Data Parallel (DDP) outperforms Data Parallel (DP) on both efficiency and flexibility. DP uses a single process to manage multiple GPUs, which causes Python’s Global Interpreter Lock (GIL) contention and limits scalability. DDP, on the other hand, uses one process per GPU, eliminating GIL bottlenecks and enabling training to scale across GPUs and even across machines.
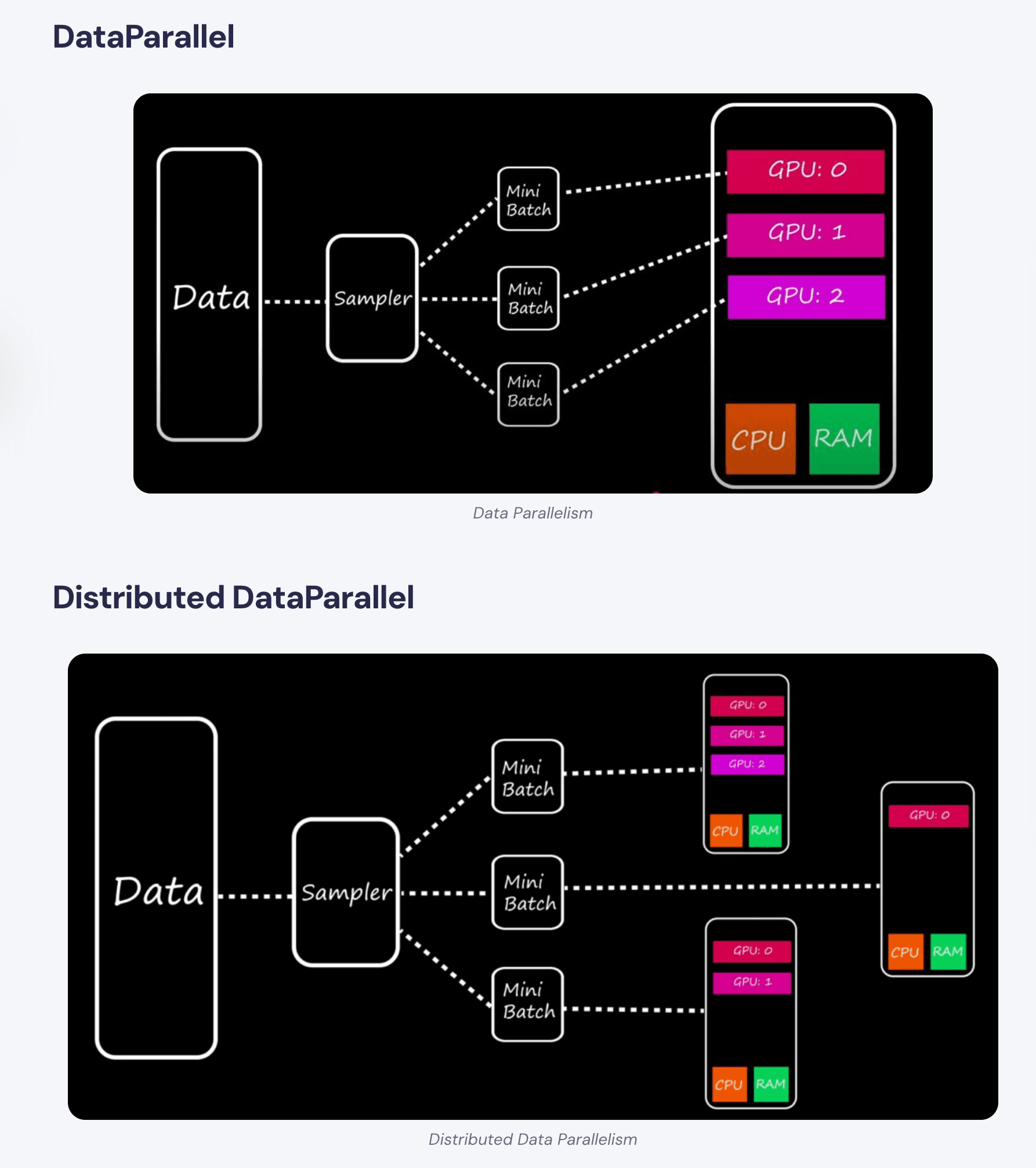
DP vs DDP workflow comparison.(source: Learn OpenCV)
How DDP Works Internally
DDP creates a process group for GPU communication, broadcasts model weights from rank 0 to other processes, and initializes gradient synchronization across replicas. During the forward pass, each GPU handles its subset of data independently. On the backward pass, gradients are bucketed and synchronized using an asynchronous all-reduce operation, ensuring consistent updates across all model replicas.
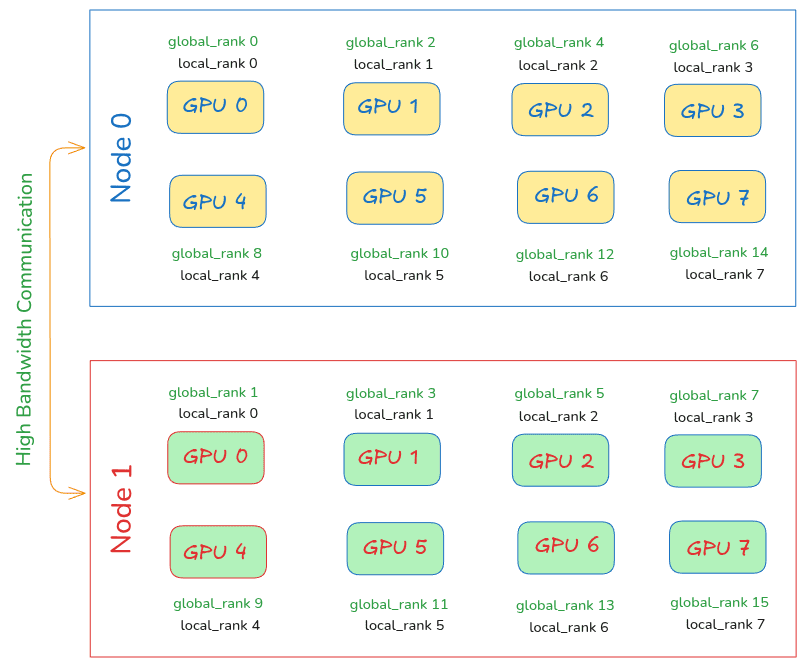
Conceptual illustration of how models are wrapped with PyTorch’s DDP. (source: Learn OpenCV)
Toy End-to-End Example
To make the concepts concrete, i tested it with a toy example using a simple neural network. It initializes the distributed environment with `torch.distributed.init_process_group`, wraps the model in DDP, and ensures each GPU processes a unique subset of data via `DistributedSampler`. This demonstration shows how multi-GPU training can be set up with minimal code changes.
Insights and Practical Tips
This implementation highlighted several practical requirements: correctly wrapping models with DistributedDataParallel, using distributed samplers so each GPU processes unique data, and understanding gradient synchronization to avoid performance issues. It also revealed the limits of standard DDP. For larger models and more demanding workloads, techniques such as Fully Sharded Data Parallel (FSDP) and pipeline parallelism become necessary for further scaling.
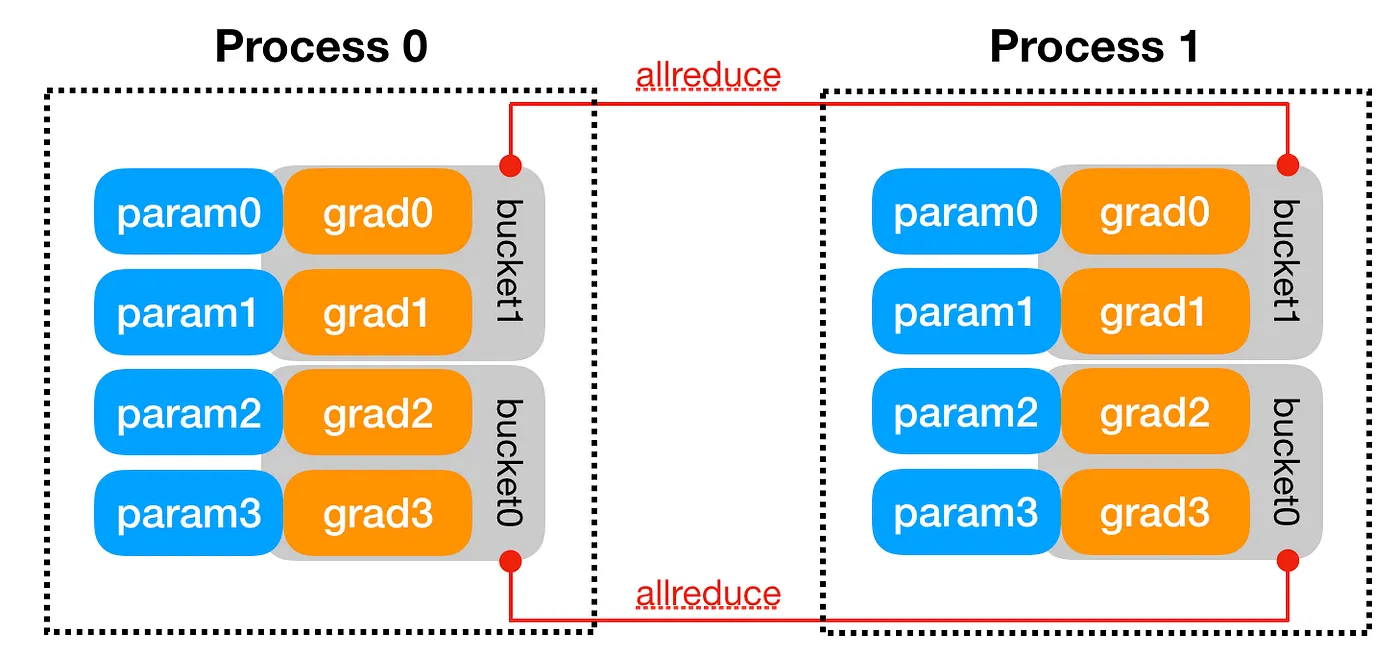
Practical engineering steps make distributed training reliable in real workflows.
Key Takeaways
This investigation into DDP clarified how distributed training enables scalable model training across GPUs and why it outperforms older parallel approaches. For anyone training larger models or working with growing datasets, understanding DDP’s architecture, process setup, and practical implementation is invaluable,especially when preparing models for production or research scaling.
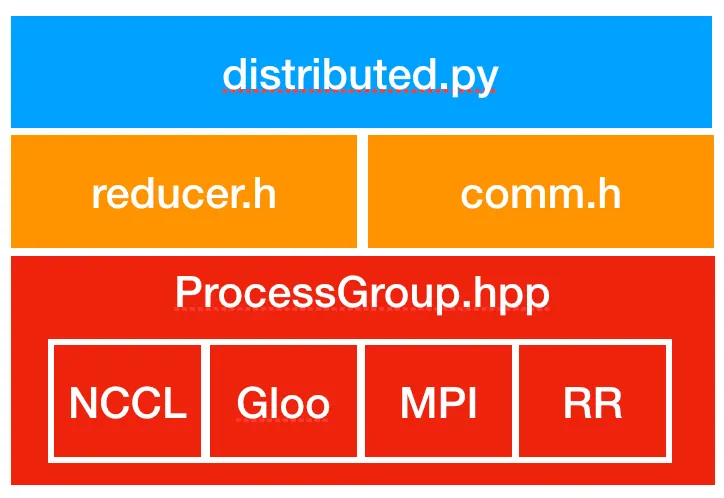
Scaling machine learning model training effectively with distributed systems.
Distributing training across GPUs reduces time and enables larger models to be trained.