Why Language Identification Is Harder Than It Looks
Automatically identifying the programming language of a code snippet seems trivial—until you encounter real-world code. Short snippets, mixed syntax, shared keywords (e.g., `class`, `def`, `{}`), and configuration files blur the boundaries between languages. Existing tools often rely on heuristics or file extensions, which fail in notebooks, chat interfaces, and pasted code blocks.
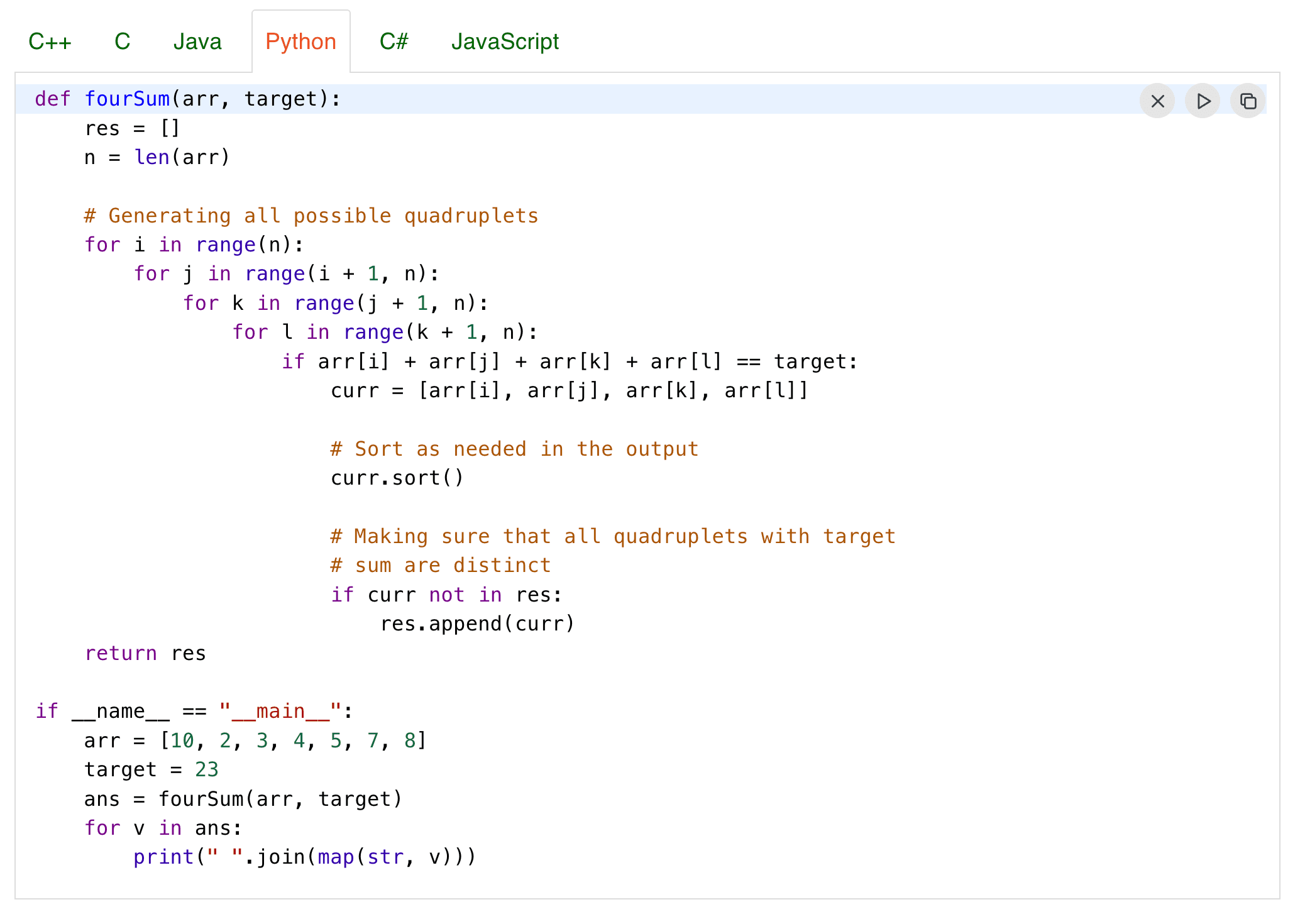
Short, context-free code snippets break rule-based language detection systems.
Treating Code as a Language Modeling Problem
I framed programming language identification as a sequence classification task by treating source code as structured text. Instead of using hand-crafted rules or file-based heuristics, I fine-tuned a Transformer-based CodeBERTa-small-v1 model to learn language-specific syntax and token patterns directly from data. Since the base model was already trained on languages like Python, PHP, and Ruby, it generalized well to short snippets, partial code blocks, and inconsistently formatted real-world code
Curating a Multi-Language Code Dataset
The model was trained on a diverse corpus spanning 100+ programming languages rosetta code dataset, including Python, JavaScript, C++, Java, Go, Rust, and more. Special care was taken to balance languages and include short, noisy snippets—reflecting how code actually appears in developer tools, chats, and documentation.
Model Architecture and Training
I fine-tuned a Transformer encoder (~83.5M parameters) for multi-class programming language classification. Instead of relying on explicit grammar rules or file extensions, the model learns language identity from token-level patterns and structural cues present in source code. Training emphasized robustness to real-world inputs, including short snippets, incomplete syntax, and overlapping keywords shared across languages.

Transformer encoders excel at capturing long-range token dependencies.
Inference Optimization for Real-World Usage
To make the model easy to use in real applications, I uploaded it to Hugging Face’s model repository so it can be loaded and run with just a few lines of code.
The model has two versions: a standard PyTorch version for development and experimentation, and an pull-request approved ONNX version for faster and more efficient inference in production systems.
Adoption and Open-Source Impact
After releasing the model publicly on Hugging Face, it gained rapid adoption and is now used by 350k+ developers worldwide. The project demonstrated how a focused, well-scoped ML system can deliver immediate real-world value when paired with strong documentation and easy deployment.
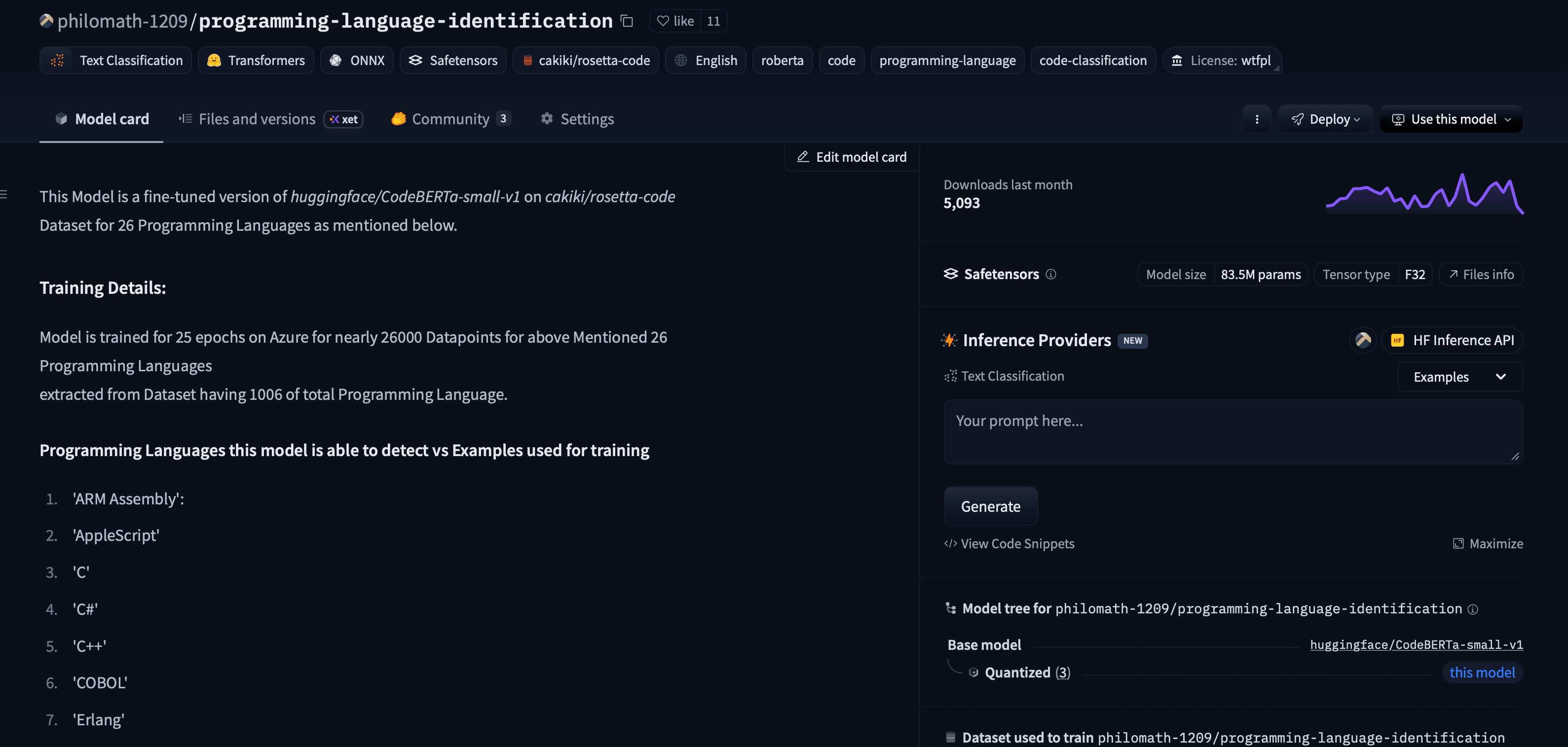
HF model page for programming language identification model.
Constraints and Trade-offs
While the architecture could scale further, training was bounded by practical compute limits. This reinforced a key lesson: for classification tasks, data quality and coverage often matter more than pushing parameter count, especially when optimizing for inference efficiency.
Key Learnings
This project strengthened my understanding of framing ML problems correctly, designing for production constraints, and shipping models that developers can actually use. It also reinforced the importance of open-source as a force multiplier for real-world impact.

Generic image of developers working on code.
Short, context-free code snippets break rule-based language detection systems.